本記事ではデータ分析の基本としてデータチェックについてやり方や注意点を概観します。
ただデータの形式や分野・データの利用目的によって手順や判断基準は異なります。
今回は筆者が扱うことの多いアンケートデータを前提にして記載していきます。
前提とスコープの明確化
本ガイドではアンケートデータが出てきてから分析を始めるまでの手順にフォーカスします。
アンケートデータとは
そもそもアンケートデータとはどういったものでしょうか。馴染みない方も多いかと思いますので確認していきます。
アンケートデータとは
・あらかじめ設計された質問票(質問+選択肢+回答形式)に対して
複数の回答者が回答した内容を1行=1回答者(または1回答単位), 1列=1質問(または1項目)という形で
表形式(CSV, Excel, SPSSなど)にしたものを指します。
統計学や調査法の教科書でも、質問票に基づいて収集されたデータを「survey data」「questionnaire data」として扱い、「1人の回答者の全回答セット」を1ケース(n数)として定義するのが一般的です。
※レコード(r数)という概念もありますが今回は触れません。
アンケートデータに固有の特性
アンケートデータの大きな特徴として挙げられるのは「主観的」な情報を含むということです。
人間が与えられた質問に対して回答するという形式のため、回答=データにも回答者の主観や自己申告の情報が反映されます。
これはPOSデータや行動ログデータのような「客観的」なデータ=行動記録とは性質が異なります。
具体的には
| 1.アンケートでは回答者の「意識・意向・評価・自己申告」といった主観的な情報を扱う |
| 2.質問文のワーディング・尺度の構成・並び順・設問遷移といった調査の設計にデータが依存する |
| 3.各種バイアスの影響を受ける(中心化傾向・初頭効果・順序バイアス・リコールバイアスなどなどなど) |
3.は1.2.によって生じるものですが以下にバイアスを生じさせないかがアンケートの設計の肝になります。
アンケートデータではデータの生成過程がデータを扱う側に委ねられているため自由度は他の形式のデータよりも高いと考えられますがその分有用なデータを生成するためには注意が必要なことが多いと思います。
今回はデータチェックの内容にフォーカスしますが、アンケートデータは設計がそもそもしっかりと出来ていないとその後の工程は全て無駄になってしまいます。
アンケートデータのチェックの観点
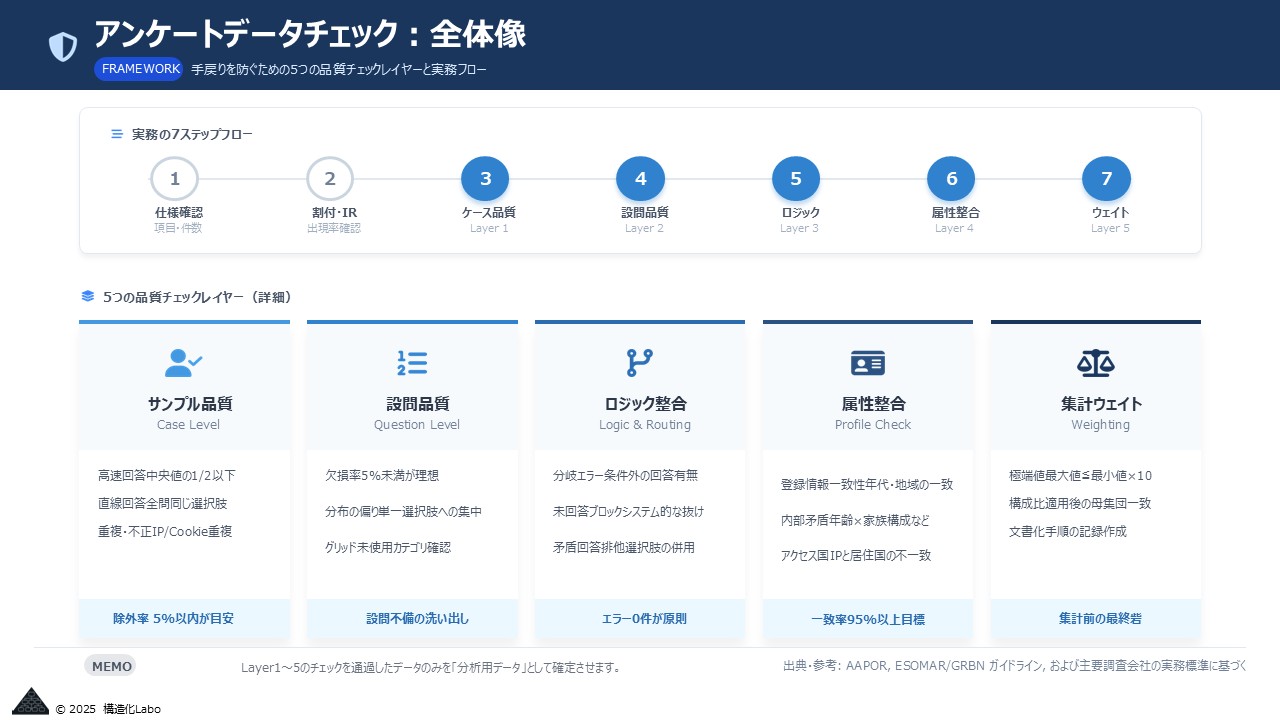
アンケートデータのデータチェックは次の5つのレイヤーに分けると整理しやすくなります。

2. 実務フロー:7ステップの詳細手順
ステップ1:メタ情報・仕様チェック
目的:「そもそも届いたデータが仕様書と同じ構造か?」を確認する段階です。
3-5までは大手の調査会社のパネルを利用していれば調査会社の方で対応済みのケースが多いですが、機械的に処理している部分が多いため、抜け漏れも多いです。その為、データを受け取った段階で改めて確認します。
1-1. 変数名・ラベル・型の突合
具体的な判別方法:
- 変数名の一致確認
- 仕様書に記載された変数名リスト(例:Q1, Q2_1, Q2_2, AGE, GENDER等)とデータファイルの列名を1つずつ照合
- 仕様書にあるのにデータにない変数、逆にデータにあるのに仕様書にない変数をリストアップ
- 変数の出現順序も確認(順序が異なると集計ツールでエラーになる場合がある)
- 変数ラベル(質問文)の確認
- SPSS形式の場合:変数ラベルが仕様書の質問文と一致しているか
- 不一致があると「Q1が何を聞いているのか」が分からなくなります。
- データ型の確認
- 数値型であるべき変数(例:年齢、満足度スコア)が文字列型になっていないか
- 日付型変数が正しく認識されているか(例:「2024/01/15」が文字列として扱われていないか)
- カテゴリ変数のコード値(例:性別が1=男性、2=女性)が仕様通りか
使用する集計・分析ツールによる部分もありますが基本的に考え方は一緒です。
1-2. ケース数(サンプルサイズ)の確認
具体的な判別方法:
- 全体件数のチェック
- 仕様書:「本調査完了サンプル n=800」→ データの行数が800行あるか
- ±数件のズレがある場合:途中でサンプル追加があったか、除外処理済みか確認
データクリーニング用にバッファ分の予備サンプルもローデータに含めてもらうのがベターです。
- セグメント別件数の確認
- 仕様書:「ターゲットA=400、ターゲットB=400」
- 実際のデータでターゲット識別変数(例:TARGET_FLAG)でグループ化して件数を集計
- 各セグメントの件数が設計通りか、大きくずれている場合は原因を追跡
- 途中離脱・スクリーニング不適格の扱い
- 「本調査完了」のみのデータか、スクリーニング離脱者も含むデータか明確化
- 完了ステータスを示す変数(例:STATUS=1:完了、2:途中離脱、3:スクリーニングアウト)で判別
1-3. 回答者IDの存在確認と一意性チェック
具体的な判別方法:
- IDの欠損チェック
- 回答者ID列(respondent_id, panelist_id, user_id等)に空欄・NULL値がないか全行スキャン
- 1件でも欠損があれば、そのレコードは特定できないため要確認
Webのアンケートの場合、欠損は基本的にありませんが概念としては理解しておく必要があります。
- IDの一意性チェック(重複確認)
- 同じIDが2回以上出現していないかチェック
- 重複がある場合の判別:
- タイムスタンプを確認し、同一人物が複数回答したのか
- 異なる調査ウェーブ(例:第1回調査と第2回調査)が混在しているのか
- データ統合時のミスで同じIDが重複付与されたのか
複数のパネルを利用している場合や複数回回答出来る設定の場合には注意します。
こちらも基本的にはありません。
- ID体系の整合性
- 複数パネルを統合する場合:パネルA由来のIDとパネルB由来のIDで桁数や形式が異なる場合がある
- 例:パネルAは「A0001〜A9999」、パネルBは「100001〜199999」のように判別
- ID形式が混在している場合、どのパネルから来たサンプルか識別する変数(PANEL_SOURCE等)があるか確認
1-4. コード表(値ラベル)の確認
具体的な判別方法:
- 選択肢コードの一致
- 仕様書:「Q1. 性別 1=男性、2=女性、3=その他」
- 実データで、性別変数に1,2,3以外の値(例:0, 9, 99等)が含まれていないか確認
- 想定外のコードがある場合:欠損値コード(例:9=無回答)なのか、データエラーなのか判別
ローデータをいじると実際の回答と異なるデータになってしまうリスクがあるのでローデータはあまりいじらないようにします。
- 多重回答のコード形式
- 方式1:複数列(Q2_1, Q2_2, Q2_3…)にそれぞれ0/1フラグ
- 方式2:1列に「1,3,5」のようなカンマ区切り
- どちらの形式で格納されているか仕様書と照合
よくある問題と判別ポイント:
- 変数の順序入れ替わり:仕様書と列順が異なる → 自動集計ツールでエラー発生の原因
- ID体系の混在:複数パネル統合時に、同じID番号が異なるパネルで重複 → 名寄せエラー
- ケース数のズレ:途中でサンプル配分変更したのに仕様書未更新 → クライアント報告時に齟齬
- 型の不一致:数値型であるべき年齢が「25歳」のように文字列で格納 → 平均値計算不可
ステップ2:サンプル構成・割付のチェック
目的:「ターゲットと割付が設計通りか」を確認します。
2-1. 割付・クォータ
- 主要属性(例:性別×年代×地域)のセルごとに件数を集計
- 設計クォータとの乖離(%ポイント差)を確認
- 極端に少ないセル(例:ターゲットのはずが n=1 など)がないか
2-2. スクリーニング条件
QSCR1〜QSCRn(スクリーニング質問)の回答と、実際に「本調査に入っているかどうか」が矛盾していないか- 例:「過去半年に◯◯を購入した人のみ本調査」としているのに、
購入なしと答えた人が本調査に入っている など
2-3. インシデンス・完了率
- インシデンス(対象者率):
本調査完了数 / スクリーニング回答数 - 完了率:
完了 / 開始
これらは調査会社や業界のベンチマークと比較され、極端に低い・高い場合はターゲット定義やリクルート方法の見直し対象になります。
ステップ3:ケース単位の品質チェック(スピーダー等)
以下が特に個々のサンプルの回答を確認する必要があるため見落としが多くなる部分になります。
大手の調査会社では機械的にOmitしてくれている企業もありますがそうではない企業もあります。
特にサンプル数が多くなるとチェックも難しくなるのであらかじめ基準を決めておきましょう。
3-1. スピーダー(speeders)
定義:「異常に短時間で回答を終えているケース」を指す用語で、中央値時間の1/3未満などを閾値にする実務が多く報告されています。
実装例:
- 全完了者の所要時間(秒)を取得
- 中央値
T_medを算出 T < T_med / 3を「強い疑義」「/2〜1/3」を「要注意」など、ランク分け
3-2. straightlining
定義:グリッド質問(マトリクス)で、同じ選択肢をずっと選び続ける回答行動。
チェック方法:
- 各グリッド設問ごとに、行(項目)に対するカテゴリのバラつきを計算
- 「すべて同一カテゴリ」のケース数をカウント
- 直線答え行動が複数グリッドで繰り返されているケースを抽出
直線回答にはいくつかのパターンがあり、1,2,3,4,5のような連番を選択するケースなどもあります。
これ以降のフェーズで回答(列)ごとの分布は確認しますがstraightliningの判別にはサンプル(行)ごとに回答を見ていく必要があります。
3-3. ナンセンス回答・コピペ回答(自由記述)
- 意味をなさない文字列(例:
asdfasdf,???) - 同一文言の大量コピペ(他回答との完全一致)
- 実務上の対処:テキストマイニング前に、こうしたケースをフラグ化(のちに除外/別集計)
3-4. 不正・ボット・重複
- IP・Cookie・指紋・メール等による重複チェック
- 典型的なフラグ:
- 同一IPから短時間に多数の完了
- 国外IPからの異常流入
- reCAPTCHA・画像認証の失敗
AAPORやESOMARは、オンライン調査における重複回答やボットの排除、ID検証の重要性を明示しています。
この部分もある程度は企業が対策をしておりますが、悪質な回答者はCookieを削除したり、複数端末、複数アカウントから回答するなど悪意を持ってすり抜ける場合もあるため、念頭においておく必要があります。
3-5. ケース除外率のモニタリング
実務情報として、大手調査会社は「品質チェックで除外されるケースは通常全完了の数%程度、10%を大きく超えると設計側の問題の可能性がある」といった判断をします。
ステップ4:質問・設問単位の品質チェック
目的:「設問レベルでおかしな動きをしていないか」を見るフェーズです。
4-1. 欠損率の確認
- 各設問ごとに
非回答・DK(わからない)・拒否の割合を算出 - ある設問だけ極端に欠損が高い場合:
- 質問文が難しすぎる/長すぎる
- モバイルでスクロールしないと見えない などの設計問題の疑い
欠損についてはWebアンケートでは基本的には回答必須のため、あまり考慮しなくても大丈夫です。
紙のアンケートでは回答に対して制御を掛けられないため欠損が多くなります。
4-2. 分布(単純集計)の確認
- 単一回答:選択肢の一つに極端な集中がないか
- 多重回答:
- 選択肢数が多いのに「その他」への異常集中がないか
- 「最大◯個まで」としているのに、システム的に制限されていない等のバグ
- カテゴリーMAXにつけたIDの確認:
straightliningの確認に近いですが、複数選択可の場合に「その他」や「特になし」など所謂、カテゴリーMAXにつけている場合、他の設問でもカテゴリーMAXにつけていたら注意が必要です。
経験則から、straightliningでないにしても適当回答の方も含まれることが多いです。
4-3. グリッド質問の詳細チェック
- 行×列の使用状況(全く選ばれていないカテゴリ/行がないか)
- 逆転項目(ポジ/ネガ混在)の処理に齟齬がないか
- 直線答えとは別に、「絵を描くようなパターン」(12345→54321など)を作るケースもあり、実務では可視化して確認する手法が使われています
ステップ5:ロジック・スキップの整合チェック
目的:アンケート特有の「分岐ロジック」が仕様通りに動いているかを検証します。
基本的にはWebアンケートでは調査の開始前に確認する部分です。
動いていることを前提に回答いただきます。
ただ、ローデータでも正しくデータが入っているかは☑します。
5-1. スクリーニング〜本設問の整合
例:
QSCR1:過去1年に◯◯を購入したか?はいのみ → 使用頻度質問QUSE1に進む
- チェック:
QSCR1=いいえなのにQUSE1に回答しているケースがないか
5-2. セクション単位の回答有無
- 特定のセクション(例:ブランド認知ブロック)に一切回答していないケースを抽出
- 途中離脱として扱うべきか、ロジックバグかを判別
5-3. 実装手段(例)
# 条件式でフラグ変数を作る
flag_route_error = 1 if (QSCR1==2 and notnull(QUSE1)) else 0
ルートエラー率を算出し、0〜ごく少数であることを確認
ステップ6:属性・外部情報との整合チェック
目的:「この回答者は本当にターゲット通りか?」を、属性・外部と突き合わせて確認します。
特にトラッキング調査では前年の結果などと見比べて確認したりすることが重要です。
サンプル数がある程度あれば、大きく変動は見られないはずです。大きな変動があればそれが、データの品質に問題があるのか、素晴らしいインサイトなのかを見極める必要があります。
6-1. パネル/会員プロファイルとの比較
パネル会社が保持する事前属性(年齢・性別・居住地等)と、アンケート内で質問した属性の一致度を確認
一致率が低いパネル・サブパネルは、データ品質面で注意が必要とされます。
6-2. 内部矛盾の検出(実務でよく使われる観点)
例:
QAGE=25歳なのに子どもの学年=大学4年生世帯年収=〜300万円未満なのに、月々の家賃=25万円かつローン返済=15万円等
ここはアンケートの実施前にロジックの設定が抜けている部分でもあり、実務上、ロジックが煩雑になりすぎるために掛けていない部分にもなります。上記の例は単純で分かりやすいですが、複雑であったり、ドメイン知識が必要な矛盾の検出は難しく、データチェックの一番重要なポイントになります。
ステップ7:ウェイト・集計準備のチェック
目的:「重み付けをした結果が、設計・母集団に整合しているか」を確認します。
7-1. ウェイト変数の技術チェック
weightの最小値・最大値・平均・標準偏差- 負のウェイト、極端に大きなウェイトがないか
- ウェイト合計が設計上の有効サンプル数、もしくは母集団サイズに対応しているか
7-2. ウェイト適用後の構成比
性別・年代・地域など、ウェイト対象属性について:
- 「ウェイト適用前の構成比」と「適用後の構成比」が、母集団分布と整合しているかを確認
単純無作為抽出の場合などは必要ありませんが、実務で単純無作為抽出の場合はあまりないかと思います。
ウエイトバックは必要な場合と不必要な場合があるため必要であれば掛けて、確認します。
7-3. ドキュメンテーション
ESOMARや学術的なガイドラインは、どのようなクリーニングとウェイト処理を行ったかを報告書に明記することを推奨しています。
クリーニングの処理をエンドクライアントに伝えることはあまりありませんがトラッキング調査などでは毎回統一しておく必要があるので基準を明文化することは重要です。
データチェックに関する推奨書籍の紹介
なるべく新しい書籍を選んでいます。

カバー内容:
- 調査目的から質問票への落とし込みフロー
- サーベイモード(郵送・オンライン・電話・対面)の選択とトレードオフ
- サンプル設計と必要サンプルサイズの考え方
- 質問票設計(設問形式、スケール、マトリクス設問の注意点、認知テスト)
- 回答率を高めるための実査運営・リマインド設計
- データ管理・基本的なウェイト付与と分析上の留意点
本ガイドとの対応関係:
- ステップ1〜2:メタ情報・サンプル構成 → 本書の「サンプル設計・質問票設計」章
- ステップ5:ロジック・スキップ整合 → 本書の「質問票設計・認知テスト」章
- ステップ7:ウェイト・分析準備 → 本書の「データ管理・基本分析」章
「そもそもの設計」を見直したい時、自分のチェックフローの穴を構造的に確認したい時に、本書の章立てを参照すると効果的です。

カバー内容:
- 生データから「統計利用に耐えるデータ」までの価値連鎖(Raw Data → Valid Data)
- 数値・テキスト・日付・時刻などのデータ表現と構造の技術的基礎
- 正規表現・エンコーディング処理を含むテキストデータのクリーニング
- 統計的データ検証(validation rules)とルールベースのエラーチェック
- エラー局在化(どのレコード・どの変数がルール違反か)のアルゴリズム
- ルールセットの保守・簡略化と、欠測値の補完(imputation)
- 小規模なデータクリーニングシステムの構築例(Rパッケージ活用)
本ガイドとの対応関係:
- ステップ3:ケース品質チェック → 本書の「外れ値・疑義ケース検出」
- ステップ4:設問品質チェック → 本書の「欠損・分布の統計的検証」
- ステップ5:ロジック整合 → 本書の「validation rules・エラー局在化」
- ステップ6:属性整合 → 本書の「ルールベース補正・矛盾検出」
- ステップ7:ウェイト準備 → 本書の「品質担保・補完処理」
Rベースの説明ですが、ルール設計やエラー局在化の考え方はPython/SQL環境にも移植可能な汎用的枠組みとして記述されています。